
How Speech-to-Text Software Functions
At its core, Speech to Text software is a complex system designed to convert spoken language into written text. The process begins with voice recognition, where the software interprets spoken words using advanced algorithms. Artificial Intelligence (AI) enhances accuracy by learning from speech patterns, accents, and variations to provide more precise transcriptions.
Voice Recognition
Voice recognition is the foundation of Speech-to-Text (STT) technology. This process involves analyzing the audio input by software and breaking spoken words into phonemes. Then, it matches the phonemes against an extensive database of linguistic patterns. Deep learning algorithms empower the software to improve accuracy continuously. This is done by adapting to individual voices and nuances.
AI Algorithms
The integration of AI algorithms has revolutionized Speech-to-Text (STT) software. Machine learning models, trained on massive datasets, enable the software to understand context, deduce meanings, and transcribe spoken words accurately into written text. This ongoing learning process ensures flexibility and efficiency in different language situations.
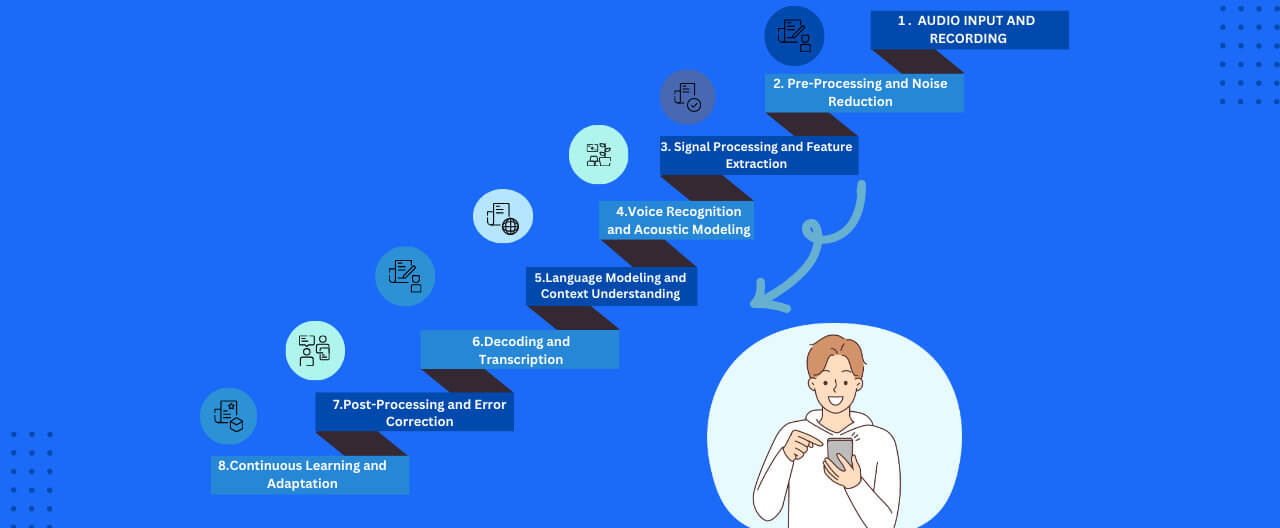
Detailed Process of Speech-to-Text Conversion
Speech to Text (STT) software enables the process of converting spoken words into written text, which involves several intricate steps. Let's understand the process in detail:
1. Audio Input and Recording
The process starts with capturing audio input, which can be a spoken conversation, lecture, or verbal communication. The quality and clarity of the audio play a crucial role in determining the accuracy of the subsequent transcription.
2. Pre-Processing and Noise Reduction
Once the audio is captured, the software performs pre-processing tasks, including normalization of audio levels and noise reduction. Advanced algorithms are employed to identify and filter out background noises to ensure the main focus is on the spoken words.
3. Signal Processing and Feature Extraction
Signal processing techniques are applied to analyze the audio waveform, and feature extraction involves breaking the audio signal into discernible features like phonemes and syllables. This step lays the foundation for the subsequent interpretation of spoken language.
4. Voice Recognition and Acoustic Modeling
Voice recognition is a pivotal aspect of STT, involving identifying and interpreting the unique characteristics of individual voices. Acoustic models map the acoustic features extracted from the audio to phonetic representations. This mapping is crucial for the software to discern different sounds and patterns in Speech.
5. Language Modeling and Context Understanding
STT software incorporates language models that understand the context of spoken words. Natural Language Processing (NLP) algorithms analyze the sequence of words and their relationships, aiding in creating coherent and contextually relevant transcriptions.
6. Decoding and Transcription
The decoded information from the audio input, including phonetic representations and language context, is then translated into written text. This process involves selecting the most likely sequence of words based on statistical probabilities and linguistic patterns. The result is a transcription that reflects the spoken content as accurately as possible.
7. Post-Processing and Error Correction
The transcribed text undergoes post-processing to rectify any errors or inaccuracies introduced during the conversion process. This may involve spell-checking, grammar correction, and contextual adjustments to improve accuracy.
8. Continuous Learning and Adaptation
Advanced STT systems can learn and adapt over time. Machine learning models continuously analyze user interactions, incorporating feedback to improve accuracy and understand individual nuances in speech patterns.
Speech-to-text (STT) software is a powerful tool that can convert spoken words into written text. This is made possible by combining artificial intelligence, signal processing, and language modeling. The result is not just a literal transcription but a contextually rich one, making it useful for personal and professional contexts. As technology advances, we can expect even more improvements in this process, enhancing speech-to-text software's accuracy and usability.
Key Features and Technologies
Real-Time Transcription
STT software excels in providing real-time transcription, allowing instant conversion of spoken words into text during live interactions, meetings, or events.
Multilingual Support
Advanced speech-to-text (STT) systems have multilingual capabilities that break language barriers and serve a global audience. This feature is invaluable in our interconnected world.
Customization
Numerous Speech-to-Text (STT) solutions offer customization features, enabling users to personalize the software to particular industries, accents, or specialized vocabularies. This flexibility enhances the software's usefulness across various sectors. For instance, some companies concentrate solely on medical transcription, necessitating adherence to HIPAA regulations.
Integration with Other Applications
Seamlessly integrating various applications, such as word processors, note-taking tools, and communication platforms, can significantly enhance user experience and productivity. The interconnectedness of these tools streamlines workflow and facilitates a more cohesive user experience. For example, many speech-to-text services have integrated with chat applications, offering endless possibilities for content creation.
Date Safety
STT software protects your data and its confidentiality. Reputable transcription services have measures to handle sensitive and confidential information, prioritizing data privacy and security to safeguard research data.
Common Challenges and Solutions
Speech-to-Text (STT) software is an impressive technology but faces some challenges. These include difficulty handling background noise, dialectal variations, Speaker-Dependent Accuracy, Ambiguous Pronunciation and Homophones, and accurately transcribing complex technical terms. To overcome these challenges, noise cancellation algorithms, dialect-specific models, and industry-specific dictionaries are used to improve the accuracy and usability of the software.
Future Trends and Developments
As technology advances, speech-to-text (STT) software is also evolving. Experts predict that STT software will improve contextual understanding and accuracy in noisy environments and be more widely used in healthcare, legal, and education sectors. The integration of natural language processing (NLP), expansion of multimodal integration, and sentiment analysis are expected to enhance the user experience, making STT software an indispensable tool in various domains. Future developments may include advanced encryption methods, user authentication mechanisms, and on-device processing to address concerns about the security of sensitive spoken content.
Discover the revolutionary capabilities of Speech-to-Text software and unleash a new level of efficiency and productivity. Whether you're a professional, student, or simply looking for seamless communication, explore the countless benefits of STT technology and integrate it into your daily routine.
Conclusion
Speech-to-text software is an innovative technology transforming how we communicate and document information. Users can unlock its full potential by understanding its mechanics and key features and addressing challenges. Looking toward the future, the evolution of STT promises exciting developments that will shape how we interact with language and technology. Let's embrace the change and journey towards a more connected and efficient future.


